
Location: [CPSC 333] [Listing by Topic] [Listing by Date] [Previous Topic] [Next Topic] Intro to Data Flow Diagrams
This material was covered during lectures on January 29, 1997.
Recall that, when principles of requirements analysis were discussed, three ``aspects'' or ``views'' of the information domain that could be analysed and modeled separately, were introduced: information content and relationships, information structure, and information flow.
We have seen that Entity-relationship diagrams and data dictionaries can be used to model information content and relationships, as well as information structure (to some extent). Data flow diagrams are useful for modeling information flow - they way data is transformed as it moves through a system.
Roger Pressman's book, Software Engineering: A Practitioner's Approach and Edward Yourdon's book, Modern Structured Analysis, contain additional information about data flow diagrams, and can serve as supplementary references. Pont's book includes a discussion of these diagrams as well.
A data flow diagram shows, processes (or ``functions''), data flows, data stores, and terminators.
Processes are parts of the system that receive inputs and generate outputs.
Processes (on data flow diagrams) have no memory or state of their own, and are assumed to work instantaneously, when data flow diagrams are used to model essential requirements.
Processes are drawn as circles on a data flow diagram, which are labeled by a ``process number'' and a ``process name.'' The process name is a short phrase that describes what the process is supposed to do. The process number is unique - that is, every process shown on a system's data flow diagram(s) has a different one.
For example, a process with process number ``1'' and process name ``Register Student,'' would be shown on a data flow diagram as follows.
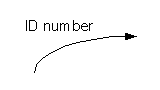
Data Flows represent information transferred between processes, stores, and external users or systems.
Data flows are represented using arrows on data flow diagrams, which are labeled by the name of the data that can be transmitted along them.
For example, a data flow that shows possible transmission of an ``ID number'' would like something like the following.
Data stores are data storage areas that are internal to the system that is being modeled. They often correspond to some part of the entity-relationship diagram for the same system.
In the data flow diagrams presented in this course, a data store will be drawn as a rectangle with the right hand side missing, labeled by the name of the data storages area it represents.
For example, a data store representing a storage area for information about ``Students'' would be drawn as follows.

Some other references, including Pont, use a different notation, in which the left hand side of the rectangle is missing, too, so that the name for the data store appears between two horizontal lines. Thus, the ``Students'' data store shown above would be drawn as follows.

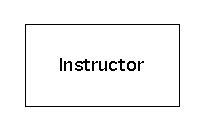
Terminators represent users of the system - people or other systems that are external to the system being modeled, whom the system being modeled communicates with, by receiving input or returning output.
A terminators is shown as a rectangle on a data flow diagram that is labeled by the name (or role) of the system user that it represents.
For example, a terminator named ``Instructor'' would be shown on a data flow diagram as follows.
Since data stores are ``passive,'' or ``static,'' it doesn't make sense to have a data flow directly from one data store to another - neither could initiate the communication.
Data stores maintain data in a logical, ``internal'' format, while terminators expect an ``external'' format. Furthermore, there's no guarantee that data supplied by terminators will be syntactically correct, or consistent, so that it will need to be checked before being used to update data stores' contents. Therefore, it also doesn't make sense to have a data flow directly between a data store and a terminator (in either direction): - at a minimum, a ``format conversion'' process would have to come between the terminator and the data store.
Since the only communication that should be modeled is communication the system could be expected to know about (and react to), and since there's no way that the system could be expected to know about communication between two terminators, it also doesn't make sense to include a data flow from one terminator to another (or to itself), either.
Finally, since processes (shown on data flow diagrams) have no memory, it also doesn't make sense to have data flows between two ``asynchronous'' processes - that is, between processes that aren't guaranteed to be active at the same time (perhaps because they respond to different external events).
Therefore, it only makes sense to have data flows
In the data flow diagrams shown in this class, communication between processes and data stores will generally be quite simple (or, highly structured). In particular, only the kinds of communication that are described below will be used.
As shown below, the arrows that represent particular kinds of communication between processes and data stores will be ``decorated'' in particular ways, in order to make it easy to see which kind of communication is being represented, just by glancing at the diagram.
As well, as described below, some kinds of communication between processes and data stores won't be shown at all (again, in the data flow diagrams used in this class). Things are omitted in order to make it as easy as possible to detect ``read only'' data stores (whose contents are never updated), or ``write only'' data stores (whose contents are never accessed); neither of these kinds of data stores should appear on a data flow diagram representing essential requirements for a system.
If a new instance is being added to a data store then this will be shown using an arrow with a cross hatch near the arrowhead, from the process making the addition to the data store to which the new record is being added:

You can assume that the process requesting the creation of the new instance will be ``informed'' of the problem if this is an attempt to add a new record, when another record with same primary key already exists, so no data flow from the data store back to the process (reporting the success or failure of the attempt to create a new instance) will be shown.
If an existing instance is being modified then this will be shown using a ``regular'' arrow (that is, the same symbol as usual) from the process making the change to the data store that includes the record to be modified:

To make the data flow diagram reasonably simple, the arrow will be labeled with the name of an entire instance, even if only one or two attributes are to be changed (and the others are to remain the same).
If it's necessary to know the old values of some of the non-key attributes of the instance in order to compute the new ones, then a data flow from the data store to the process (showing the old version of the instance being read) will also be displayed. Otherwise, no such data flow will be shown. As well, no status message from the data store back to the process (showing success or failure of the update) will be shown on the data flow diagrams used in this course.
If an existing instance is being deleted then this should be shown using an arrow with an X near the arrowhead, from the process deleting the instance to the data store from which the instance will be deleted.
To make the diagram simple, this will be labeled with the name of an entire instance, even though it's almost certainly just the values of the attributes in the ``primary key'' that are being transmitted to the data store:
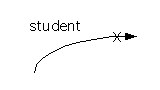
As above, no status message from the data store back to the process (signalling the success or failure of the attempted deletion) will be shown.
If you want to read a single instance from a data store then it's (generally) necessary to supply the values for all the attributes in the store's primary key. A process might also want a set of (all) records in a data store satisfying some criterion - perhaps, with some given value for some non-key attribute, or perhaps something more complicated than that.
In data flow diagrams that are shown in this course, the data flowing from the process to the data store, supplying values for one or more attributes before the ``read,'' won't be shown. Neither will the transmission of any status message from the data store back to the process. Instead, a single data flow from the data flow to the process will be shown. This won't be ``decorated'' in any way (so, it will look like the arrow for an ``update,'' except that it will point in the other direction), and it will either be labeled with the (singular form of) the name of one instance, if at most one instance is to be read, or of the plural form of this name, if more than one instance might be returned.
On a large diagram (that includes a lot of processes), it may be useful to show more than one copy of the same data store or terminator, in order to reduce clutter that would otherwise be caused by having data flowing from numerous processes to a single copy. (On the other hand, processes aren't generally duplicated on these diagrams.)
If you do use more than one copy of a data store or a terminator, then you should draw a small diagonal line in the upper left corner of every copy of the duplicated data store or terminator. You'll notice that this has been done to show that the data store ``Students'' and the terminator ``Instructor'' have both been duplicated, in the large example that follows.
Location: [CPSC 333] [Listing by Topic] [Listing by Date] [Previous Topic] [Next Topic] Intro to Data Flow Diagrams