Location: [CPSC 333] [Listing by Topic] [Listing by Date] [Previous Topic] [Next Topic] Relationships
This material was covered during Lectures on January 23, 1997.
This next version of the system can be used to keep track of information about students who are registered in several courses. While it will probably be necessary (much later during analysis and development) to place a bound on the number of courses the system can know about at the same time, we'll start by treating this as unlimited (just as we're doing for the number of students).
As before, each student has a unique ID number, as well as a first name, middle initial, and last name that aren't necessarily unique.
Each course has a discipline code (a short character string), a course number (a positive integer), and a course title (a longer character string). No two courses have the same discipline code and also the same course number at the same time. However, several courses can have the same discipline code, and several courses can have the same course number, as well (but, not both at once). Course titles are not necessarily unique.
System functions are extended, but also changed in some cases. It should now be possible to add information about students, even if though those students haven't registered in any courses (yet). It should also be possible to add or change information about courses.
Any student can be registered in or have passed zero or more courses. Any course can have zero or more students registered in it or passed by it.
Now, it is necessary to provide both a student's ID number and the discipline code and course number of a course in order to register a student in a course, or indicate that a student has passed or withdrawn from a course.
A more complete description of this version of the system is available. However, these are all the details that we will need at this point.
Course will be added as an entity in the ERD for this version of the system. The primary key for ``Course'' will consist of a pair of attributes, discipline code and course number. The entity will also have a third, ``non-key'' attribute: course title.
As before, each entity in the system's ERD will correspond to a table of stored data. There will be a column in the data table for each of the entity's attributes. The number of rows in the table, and the information written in them, will change over time as the system is used; each row will correspond to some instance of the entity that the system currently knows about.
Thus, this system's data tables will include two data tables corresponding to the ERD's two entities:
These tables don't include all the information the system will need - note that they include no information about which students are registered in (or have passed) which courses. We'll either need to change our existing tables, or add new ones, in order to store this extra data.
Here are some options we'll reject, and the reasons for rejecting them.
We could try to extend one or the other (or both) of the existing tables. For example, we could try to add columns to the table for ``Course,'' in order to include ID numbers for the students registered in each course (as well as for students who've passed it).
However, we'd still like it to be the case that this table only has one row for each existing course - otherwise, we'd have to list the same (non-key attribute) course title for each course, over and over again. This kind of redundancy in data tables is highly undesirable, partly because it's wasteful, but also because it increases the chance that contradictory information could be entered (in this case, by having different course titles listed for the same course in different rows of the table), or even that information could be missed completely (a possibility for a course with no registered students currently in it).
Now, we could create columns (maybe, one each for ``registered students'' and for ``students who have passed'') that can contain data corresponding to lists or arrays of ID numbers of students. In effect, we'd be adding new attributes of the entity ``Course'' with complex data types. This fails to satisfy a goal we stated earlier - that each attribute should have an ``elementary'' data type - so we'll discard this option, for that reason.
Alternatively, we could try to add a column to the table for each registered student. This would violate our requirement that the ``layout'' of the data tables (including the number of columns in the table) should be ``static:'' We don't want it to be possible for each row of the table to be able to have ``meaningful information'' in a different number of columns, and we certainly don't want the maximum number of columns required to change (or be unbounded) as the system is used! Instead, every row of the table should include meaningful information in every column. In other words: every instance of the entity should have a value defined for every one of the entity's attributes, and it should not be possible to change the number of attributes through normal system use.
So, we aren't going to be able to extend the ``Courses'' data table to include information about students who've registered in or passed the courses that it lists. We won't be able to extend the ``Students'' data table to include this kind of information either, because exactly the same problems would arise if we tried to do this, too.
Another alternative would be to create two tables for each course, listing the ID numbers of students registered in that course in one of these tables, and listing the ID number of students who've passed it in the other. Note that each one of these tables would have a ``static layout,'' in the sense that each table would have exactly one column (for ID numbers), and that each row of the table would always have a single meaningful value stored in that column.
However, this option will also be rejected - this time, because we would also like the number of tables used by the system to be a fixed constant - and not something that depends on the number of rows that currently appear in some other table (in this case, the number of rows in the ``Courses'' table).
We'll reject the use of two separate tables (of discipline codes and course numbers) for each student, for the same reason.
Now, we're ready to describe the approach that can and will be used. We'll add (exactly) two more tables of data:
A ``registrations'' table with three columns - for ID number, discipline code, and course number - that is, all the attributes in the primary keys (only!) for the entities ``Student'' and ``Course.''
To show that a given student is registered in a give course, we would have the ID number for this student and the discipline code and course number for this course all listed in one row of this table (and we wouldn't have all this information in one row otherwise).
A ``completions'' table, with the same three columns as the ``registrations'' table - used to keep track of the students who have passed (rather than are currently registered in) courses.
Note that the ``registrations'' and ``completions'' aren't quite the same as the tables for ``Courses'' and ``Students'' - their data tables list attributes in the primary keys of (fixed) other entities, and they don't include any attributes of their own. Thus, they correspond to connections, or relationships between entities that appear in the ERD.
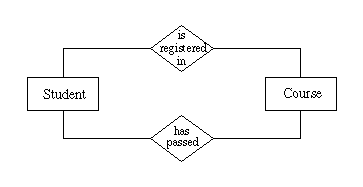
An entity relationship diagram for version of the system is as follows.
A plain text approximation of this picture is also available. This ``corresponds to'' the above data tables (in a sense that should be clearer later in the term, but that might not be clear now).
This diagram includes two entities - ``Student'' and ``Course.'' The entity ``Student'' has one less attribute than the corresponding entity in the ERD for the first version of the system, since the attribute ``status'' is no longer used.
The diagram also includes two relationships: ``is registered in'' and ``has passed,'' corresponding to the data tables ``registrations'' and ``completions'' that have already been described.
My own ``naming convention'' - which you aren't required to follow - has relationships in ERDs named by short transitive ``verb phrases,'' and has data tables named by nouns or noun phrases. It'd also be acceptable to use nouns as the names for relationships - but I think this makes the ERD a bit less readable.
The primary key for ``Student'' is (still) a set that includes a single attribute, ``ID number.'' The entity ``Courses'' has three attributes - ``discipline code,'' ``course number,'' and ``course title,'' and a primary key consisting of a pair of these attributes - ``discipline code'' and ``course number.''
Note that each of these entities corresponds to a table of data, in which columns correspond to attributes and rows correspond to instances of the entity, as before.
The relationships ``is registered in'' and ``has passed'' do not have attributes of their own - ``plain'' relationships never do. These represent connections between instances of the entities they relate.
Since both of these relationships connect the entity ``Student'' and the entity ``Course,'' each of these two relationships corresponds to a (different) table of data. Each of these two tables will have three columns - one for a student's ``ID number,'' and two more for a course's ``discipline code'' and ``course number.'' That is, there are columns for all the attributes in the primary keys of the two entities connected by the relationship. There will not be a column for any of the entities' other attributes - hence, there is no column here for any part of a student's name, or for a course's ``course title.''
In general, a relationship in an ERD connects two or more entities in the diagram - or can connect an entity to itself. A relationship usually connects exactly two entities, but three (or even four-way) relationships can occur.
Each relationship can correspond to an additional system data table (we'll see later that it can also correspond to an extension of an entity's table in some cases). As the above example suggests, (plain) relationships never have attributes of their own. Instead, the data table for a relationship lists the primary keys of (instances of) entities connected by the relationship.
Location: [CPSC 333] [Listing by Topic] [Listing by Date] [Previous Topic] [Next Topic] [Relationships]