Location: [CPSC 333] [Listing by Topic] [Listing by Date] [Previous Topic] [Next Topic] Introduction to Testing
This material was covered during lectures on March 24, 1997.
Many software engineering textbooks include sections on software testing. Pressman's Practitioner's Guide does, and is the main reference for this material. Fortunately, most of this material is included in the third edition of this book (as well as the fourth), so it is available to you.
The following ``principles'' are appropriate for the kind of software, and software projects, discussed in this course. That is, these make sense if software is too large or complex to be developed by a single person, or for all the details to be retained by a single person at once.
Testing is the process of examining or executing a program with the intention of finding errors, and not to somehow deduce (or prove) that the software is error-free.
It must be assumed that the program will include numerous errors when it's first developed.
Furthermore, the cost of correcting an error increases, drastically, as development proceeds. Therefore, the sooner an error is found, the better!
So, we'll consider a ``good'' test to be one that has a high probability of finding an as-yet-undetected error, and we'll consider a test to be ``successful'' (at least, early on) if it does find an error!
It is impossible to completely (or exhaustively) test any nontrivial module or system.
In general, a single test gives information about the behaviour of the program on only one input (or, at best - if the program has been well designed and implemented using ``structured'' techniques - one ``range'' or ``set'' of inputs).
If hardware and software bounds (maximum sizes of integer inputs, maximum array lengths, etc.) are ignored, then the number of inputs - and the number of tests needed for complete or ``exhaustive'' testing - is generally infinite.
Even if these hardware and software limits are included, the number of tests needed for ``exhaustive'' testing for a function with only one (simple) input is large - and the number of tests needed grows exponentially as the number of input parameters increases.
Thus, you won't need your module to have very many parameters before you're forced to conclude that the time needed to complete ``exhaustive testing'' would exceed the lifetime of the universe, even when assuming that the time needed to complete a single test is shorter than is currently possible.
Testing takes creativity and hard work.
You can think of this as a consequence of the second point made above: Since exhaustive testing is impossible, the best we can hope for is a small set of tests that somehow ``cover'' most plausible cases. Designing a set of tests that has this property is nontrivial.
Test results should be recorded, for comparison with results that are later obtained during ``retesting,'' after changes have been made - in order to look for any unexpected or undesirable ``side effects'' of changes, as well as to see whether the changes helped.
It is also possible to conduct various kinds of statistical analyses on the test data (that are beyond the scope of this course) in order to try to estimate the ``quality'' or the ``reliability'' of the software.
Testing is best done by several *independent testers, and not (entirely) by the developers who designed and coded the system.
One very common source of errors is a misunderstanding of system requirements. If developers misundersand the requirements, they are also liable to ``test the wrong thing'' - designing tests based on their incorrect understanding of what the system is supposed to do. It's also possible that developers can become too ``attached to'' their own work and will be reluctant to be critical of it.
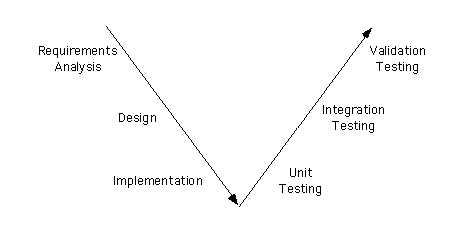
So far, development has proceeded from a ``general'' view of the entire system to a ``specific'' consideration of individual modules. Since the design of many tests can (and should) take place as development proceeds, test design can proceed in the same way.
However, the execution of tests should generally be performed, in reverse order, so that individual modules are thoroughly tested before larger (sub)systems are considered.
In the list given below, we'll consider testing stages in order of test execution, rather than design.
During Unit Testing, each module in the system is individually tested.
After unit tests have been performed, and modules have been considered to be acceptable, the modules are combined (or ``integrated'') together in order to form progressively larger and more complicated subsystems - and each subsystem is tested before it is combined into an even larger system.
When errors are found, it is generally necessary to ``roll the process back:'' Changes are made to one or more of the modules in the subsystem. ``Unit testing'' must be conducted again for the modules that have been changed - and integration tests for the subsystems containing these modules must be repeated as well, in order to try to ensure that the detected problems have been eliminated, and no new problems caused, by the changes. This process of ``rolling back'' and repeating tests, after changes have been made, is called regression testing.
Eventually the entire system is combined together and tested.
The tests described above are conducted, for the most part, by software developers - either the developers who specified, designed, and/or implemented the system, or an independent group of testers.
During validation testing, (some of) the people who will be using the delivered system begin to use the system, partly under ``typical working conditions.'' This can provide a final check on the requirements specification, as well as the software to be delivered.
Software is often part of a much larger system that includes hardware, a data base, people, etc. After the software has been tested it is necessary to test the system as a whole.
Some of this material assumes the use of ``structured'' (or, ``function-oriented'') techniques for development. Note, for example, the attention early on to modules, rather than classes.
Material about ``object-oriented testing'' is now emerging. This will be discussed, briefly, later on in the course.
Both Static Testing and Dynamic Testing should be conducted.
Static Testing is testing done directly on the source code of a program, without executing it.
Types of static testing that can be performed manually include the following.
Automated static testing can produce lists of errors, highlight questionable coding practices, or flag departures from coding standards.
Static analyzers can also provide information about the structure of code, including symbol tables, call graphs (showing which modules are called by which other modules), flow graphs (which we'll use during ``path testing,'' which will be discussed next), lists of parameters passed to each module, etc.
Dynamic Testing tests the behaviour of a module or program during execution.
There are two major approaches to dynamic testing: Black Box Testing (which is often also called Functional Testing) and White Box Testing (which is often also called ``Structural Testing'').
Black Box Testing, or Functional Testing, includes the development and execution of tests that are based on the functional requirements of programs, as given by requirements and module specifications.
Black box testing is useful for finding
While some black box testing is performed during unit testing, it is used more extensively during later testing stages.
``Exhaustive'' black box testing is generally impossible, because there are too many possible inputs to try them all.
White Box Testing, or Structural Testing, includes the design and execution of tests that are based on the internal workings and operations of a module.
White box tests typically try to ensure that
This type of testing is conducted at earlier stages - most extensively, during unit testing.
It isn't generally possible to conduct ``exhaustive'' structural testing, because there are generally too many possible control paths through a module for all of them to be checked using a reasonable amount of time.
It might seem that tests based on requirements - black box tests - are sufficient. However,
While you might be able to make effective use of a source code debugger, such as gdb, in order to implement some of the tests that will be described, it's generally necessary to write some additional code as well. For example, it's generally necessary to use stubs and drivers for modules during both unit testing and integration testing.
In order to test a module (during unit testing) or subsystem (during integration) we may need to provide something to replace the lower level modules that it calls. The replacements for lower level modules that one provides for use in unit testing and integration testing are called stubs.
Each stub should should have the same name and parameters as the lower level module it replaces. The stub might be
It's possible that you might be able to forego (most of) the development of a stub, by making careful use of a code debugger (such as gdb) instead. For example, you might set a breakpoint at the point of entry of a simple function, inspect the inputs that have been passed to it, and then set the values that are to be returned.
However, this would presumably require that tests be performed manually, rather than having them automated. It's not clear that it could be made to work at all - at least, not using the debuggers available on our Unix system here - if the module's inputs or outputs include (data structures based on) pointers.
A driver is a module that's used for testing and that has the job of calling the module or subsystem that's currently being tested, and validating (or, possibly just reporting) the output that this subsystem returns to it.
A driver might prompt a user for inputs, read them from a lookup table, or might even generate them randomly (from some appropriate sample space).
After calling the module or subsystem to be tested, it might simply report the outputs it received from the subsystem or it might check them using a lookup table, or run some sort of ``validation'' procedure to confirm that the subsystem functioned correctly.
It should be noted that the ``validation'' of an output can sometimes be much simpler - and done more quickly - than ``computing the output from the input'' might be. For example, if you are given a module (or subsystem) that receives a positive integer x as input, and is supposed to return the (floor of the) square root, y,of the input x as output, then you do not need to write (or call) a ``square root'' algorithm in order to validate the output. Instead, it's sufficient to use a squaring (or multiplication) algorithm, and check that
y2 <= x < (y+1)2
It's also useful to add code that can be ``enabled'' during checking and ``disabled'' after checking is completed. This is particularly useful during integration testing (and will be described when this topic is discussed).
Source code debuggers for C and C++ are available on all commonly used computing platforms. The debugger gdb is widely available on Unix systems and (unlike a number of other debuggers, including dbx) it's clear that it supports C++ as well as C. I recommend that you check the man page for one or both of these.
Location: [CPSC 333] [Listing by Topic] [Listing by Date] [Previous Topic] [Next Topic] Introduction to Testing