|
|
| |
| Jörg Denzinger's
Research |
|
Learning Cooperative Behavior - The OLEMAS System
The goal of the OLEMAS project is to get insight into learning cooperative behavior. Cooperative behavior in a group of agents means that there is a goal that the agents have to achieve and that the behavior of each agent, i.e. the actions it performs, aims at helping to achieve this goal of the group. With respect to learning, there are in principle two approaches how learning can be achieved for an agent, namely offline learning and online learning. The following picture shows the components of a learning system, according to Langley:
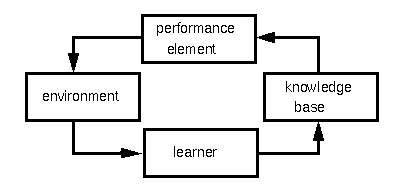
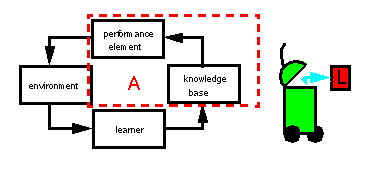
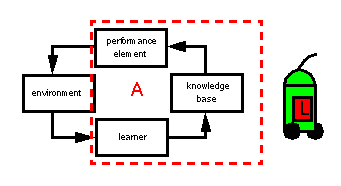
If we want to build learning agents then we have the following possibilities:
|
|
| Offline learning: agents learn before they act in "real world" |
Online learning: agents learn while working on task in "real world" |
Naturally, in a multi-agent system we can have both online and offline learning agents and, in fact, on- and offline learning are only two extrenes in a spectrum as our approach in OLEMAS has shown.
In order to do research towards learning cooperative behavior, we have to choose concrete concepts for the following ``problems'':
- agent architecture,
- learning method, and
- application domain.
Obviously, the three problems are connected, but our goal was to find concepts for learning cooperative behavior that
- are generally applicable
- use not much domain knowledge
We think that the following concrete realizations provide good solutions to the problems above with respect to our goals.
- Prototypical Situation-Action-Pairs
together with the Nearest-Neighbor-Rule
as agent architecture:
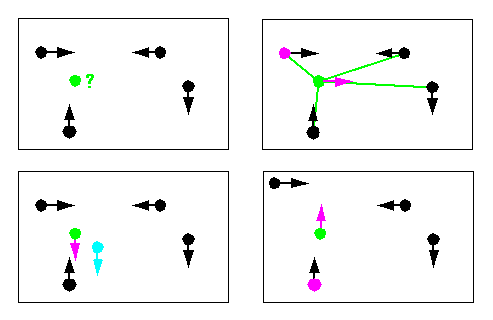
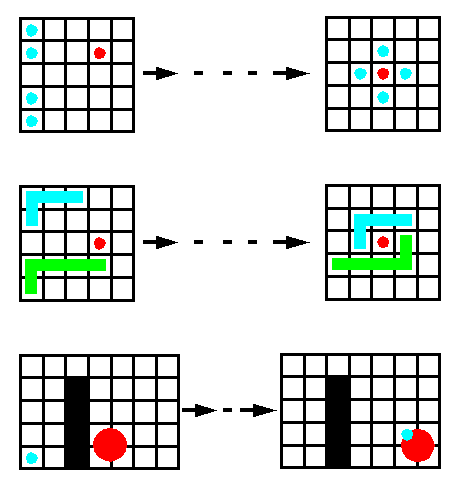
Each agent decides about its next action by looking into a set of situation-action-pairs (its strategy) for the pair with the situation that is most similar to the situation in which the agent is currently in. Then it performs the action of this pair. So, in the picture below, if the green dot in the first picture represents the actual situation, then the magenta dot in the second picture is the situation nearest to the actual one and therefore the action associated with it is performed. A situation is usually described by a vector of numerical values. The pictures below also show how to modify a strategy by either adding new situation-action-pairs (the blue one) or by changing the situation vector of an existing pair (in the last picture).
- An evolutionary approach as
learning method:
Evolutionary approaches use a set of individuals (a population) as search states and generate new individuals by combining features from good individuals in the population. How good an individual is is represented by its fitness. Over time, the fitness of the individuals usually gets better.
In OLEMAS an individual is a strategy for each of the agents for which cooperative behavior should be learned. The fitness of an individual is determined by letting all the agents with the associated strategies try to perform the given task (in a restricted simulation) and by measuring the success the team had (this naturally depends on the task the team has to do).
- The many possible variants of the Pursuit
Game as application domain:
The Pursuit Game is a multi-agent game in which a group of hunter agents has to catch a prey agent on an infinite grid by surounding it. This game can be varied with respect to the following features (this list is not complete):
- form of grid
- individual agent:
- shape and size
- moves and actions
- speed
- perception and communication
- memory
- hunter team:
- number of hunters
- type of hunters
- prey:
- type
- strategy
- neutral agents
- number
- type
- start situation
- goal situations
The following picture shows a few variants of this game:
Our OLEMAS system implements these three concepts to give us a testbed
for both offline and online learning (OLEMAS stands for On
{kind=link}
OLEMAS basically consists of an Evolutionary Learning Component and a Simulation Component. The Simulation Component is able to simulate many variants of the pursuit game (having the various features from above as parameters). The different agents that can occur in the game variants are realized in an Agents Component. The Evolutionary Learning Component basically works with a population of agent strategies that are tried out using the Simulation Component.
In Offline-Mode, the Learning Component of OLEMAS is given a variant of the pursuit game, it generates a random set of individuals as start population and then generates new individuals (grouped in generations) until an individual, i.e. a strategy for each learning agent, is found that solves the game variant (or was successful in a given percentage of trials, if random factors are involved in the game variant).
The general idea of our online-learning approach is to use the offline-learning in agents in form of a special action "learn". This action "learn" is performed by an agent within a given time interval (depending on the performance of the agent so far) and takes a certain number of time units (in which the game the agent is acting in, the "real" world, commences). The action "learn" consists of invoking a new instance of OLEMAS and its offline-learner, using a very limited simulation, and merging the nest strategy found during learning with the current strategy to form a new, and hopefully better, strategy of this agent.
Naturally, the new instance of OLEMAS has to be given a game variant. This variant uses as start situation the predicted situation the agent will be in after performing "learn" (due to random factors and possibly insufficient data about other agents only an uncertain prediction is possible). The individuals of the Evolutionary Learning Component consist of only one strategy, the one for the learning agent. The behavior of the other agents is either controlled by their real decision functions (that they also use in the "real" game, this can be seen as the result of communication with these agents) or by a model the agent has made of them during the run of the "real" game. To model an other agent, an agent assumes that this other agent uses prototypical situation-action-pairs and the nearest-neighbor-rule itself. The modeling agent then collects all situations that occured so far (or a good subset of them) with the actions the other agent performed in these situations and uses them as the situation-action-pairs in its model.
Naturally, these two "tricks" (the action "learn", to use offline-learning for online-learning, and modelling other agents using observed situation-action-pairs and the nearest-neighbor-rule) can be used for all offline-learning approaches. And the use of the action "learn" also shows that on- and offline-learning are not totally different approaches but extremes in a spectrum of possibilities. The farther (i.e. more steps into the future) the simulations used during "learn" go, the more online-learning assembles offline-learning (and a kind of planning what to do, which is exactly what the result of offline-learning should be: a strategy that is successful, i.e. a plan to win the game).
We have extended our basic work on OLEMAS in many different ways:
- Dealing with substitution of one agent by another agent with different abilities in an experienced team
- Looking at alternative fitness functions
- Improving the modeling of other agents by use of stereotypes
- Allowing for a human coach to provide a skeleton set of Situation-Action-Pairs and using learning to enhance this set.
For more details about our work on OLEMAS, please refer to the papers cited on our OLEMAS bibliography page. A list of the persons that are or were involved in developing OLEMAS can be found here. You might also be interested in our work on using learning of behavior to test complex systems.

|
back to our page on multi-agent systems. |
Last Change: 5/12/2013